
Hmelex
Постоялец
- Регистрация
- 15 Апр 2008
- Сообщения
- 552
- Реакции
- 129
- Автор темы
- #1
Подскажите пожалуйста Как можно скопировать текст с сайта
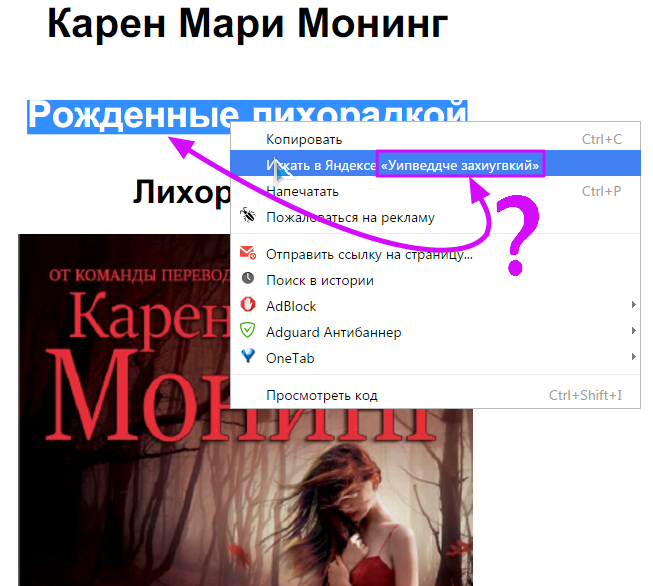
Там как мне понятно стоит разная кодировка для разных страниц.
Текст вроде читается нормально но скопировать никак не получается")

Декодер Лебедева тоже выдает абракадабру.
Помогите пожалуйста.
Может у кого то получиться скопировать текст.
Для просмотра скрытого содержимого вы должны войти или зарегистрироваться.
Там как мне понятно стоит разная кодировка для разных страниц.
Код:
docManager.addFont(1, "", "ff1", "Arial, Arial, Helvetica, sans-serif", "normal", "normal");
docManager.addFont(0, "", "ff0", "Comic Sans MS, Comic Sans MS5, cursive", "normal", "normal");
docManager.addFont(3, "", "ff3", "Comic Sans MS, Comic Sans MS5, cursive", "normal", "normal");
docManager.addFont(2, "", "ff2", "Arial, Arial, Helvetica, sans-serif", "normal", "normal");
docManager.addFont(5, "", "ff5", "Arial, Arial, Helvetica, sans-serif", "normal", "normal");
docManager.addFont(4, "b", "ff4", "Arial, Arial, Helvetica, sans-serif", "bold", "normal");Текст вроде читается нормально но скопировать никак не получается
Декодер Лебедева тоже выдает абракадабру.
Помогите пожалуйста.
Может у кого то получиться скопировать текст.
Последнее редактирование: